

Many scientists say they dislike writing, but I want to persuade you not to be one of them. Writing not only is the way to convince folks how important your work is, but it can be a key part of doing good science in the first place. Your work must be explainable in a concise and logical way … or else it may not be logical!
And writing can be fun, once you realize it’s another more-or-less scientific puzzle to solve: how to explain what you’re doing to a target audience (or audiences). What’s the one-sentence version of your work? The three-sentence version? How would these change for more general or more technical audiences?
Continue reading

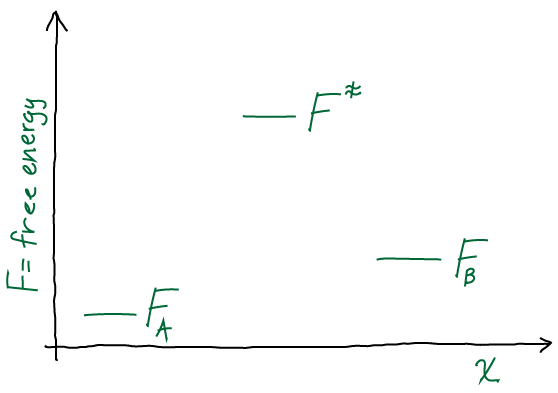
 ? But that was relaxation to equilibrium. Relaxation to a non-equilibrium steady state (NESS) is more interesting.
? But that was relaxation to equilibrium. Relaxation to a non-equilibrium steady state (NESS) is more interesting.

